向后兼容性(Backward Compatibility)
最终更新: 2024/03/21
本章介绍关于 向后兼容性(Backward Compatibility) 需要注意的问题. 下面是 "不要做" 的建议:
要考虑使用:
详情请参见 用于增强向后兼容性的工具.
向后兼容性(Backward Compatibility)的定义
一个好的 API, 非常重要的一点就是向后兼容性. 向后兼容的代码, 使得新 API 版本的客户能够使用他们过去在旧 API 版本中曾经使用过的相同的 API 代码. 本节介绍为了让你的 API 保持向后兼容性所应该考虑的要点.
在我们讨论 API 时, 至少有三种类型的兼容性:
- 源代码兼容(Source)
- 行为兼容(Behavioral)
- 二进制兼容(Binary)
关于兼容性类型的详细讨论
如果你能够确信你的客户的应用程序能够使用你的库的新版本正确的重新编译, 那么你可以认为库的版本之间是 源代码兼容的(Source-compatible). 通常来说, 除非变更非常微小, 否则源代码兼容的实现和自动检查都是非常困难的. 在任何 API 中, 总是会存在一些特殊情况, 某些修改会导致破坏源代码兼容性.
行为兼容性(Behavioral Compatibility) 保证任何新的代码都不会改变原来代码行为的语义, Bug 修正除外.
库的 二进制向后兼容(Binary Backward-compatible) 版本可以替换这个库以前编译的版本. 使用这个库的以前版本编译的任何软件, 都应该能够继续正确工作.
在不破坏源代码兼容性的情况下, 也有可能会破坏二进制兼容性, 反过来也是如此.
保持二进制兼容性的某些原则是非常显而易见: 不要直接删除 Public API 的某些部分; 相反, 应该 废弃(deprecate) 它们. 后面的各节介绍一些比较少为人了解的原则.
"不要做" 的建议
不要向既有的 API 函数添加参数
向一个 Public API 添加无默认值的参数, 是一种破坏性变更(Breaking Change), 因为既有的代码将没有足够的信息来调用变更后的方法. 即使添加 默认参数 也有可能会破坏你的使用者的代码.
下面的例子演示向后兼容性如何被破坏, 其中包含两个类: lib.kt 表示一个 "库", client.kt 表示这个 "库" 的一个 "客户端".
在真正的应用程序中, 这样的 "库/客户端" 结构是很常见的.
在这个示例中, "库" 有一个函数, 计算 Fibonacci 数列的第 5 个元素.
lib.kt 文件内容如下:
fun fib() = ... // 返回第 5 个元素
我们从另一个文件 client.kt 中调用这个函数:
fun main() {
println(fib()) // 返回 3
}
我们来编译这些类:
kotlinc lib.kt client.kt
编译结果是 2 个文件: LibKt.class 和 ClientKt.class.
我们来调用客户端, 确认它能正常工作:
$ kotlin ClientKt.class
3
这段代码的设计远远不够完美, 而且出于学习的目的, 使用了硬编码. 它预先定义了你想要从数列中获取哪个元素, 这样做是不正确的, 而且违反了代码清晰的原则. 我们来重写这段代码, 保持相同的默认行为: 默认情况下它会返回第 5 个元素, 但也可以指定你想要取得的元素序号.
lib.kt:
fun fib(numberOfElement: Int = 5) = ... // 返回指定的元素
我们只编译 "库": kotlinc lib.kt.
我们来运行 "客户端":
$ kotlin ClientKt.class
结果是:
Exception in thread "main" java.lang.NoSuchMethodError: 'int LibKt.fib()'
at LibKt.main(fib.kt:2)
at LibKt.main(fib.kt)
…
发生了 NoSuchMethodError 错误, 因为编译之后 fib() 函数的签名发生了变化.
如果你重新编译 client.kt, 它又可以正常工作了, 因为它会注意到新的函数签名.
在这个示例中, 在保持源代码兼容性的同时, 破坏了二进制兼容性.
使用反编译(decompilation)来理解具体细节
这段解释只适用于 JVM 平台.
让我们对修改前的 LibKt 类调用 javap:
> javap LibKt
Compiled from "lib.kt"
public final class LibKt {
public static final int fib();
}
对修改后的类也做同样的调用:
> javap LibKt
Compiled from "lib.kt"
public final class LibKt {
public static final int fib(int);
public static int fib$default(int, int, java.lang.Object);
}
签名为 public static final int fib() 的方法被替换为一个新的方法, 签名为 public static final int fib(int).
同时, 一个代理方法 fib$default 将调用委托给 fib(int).
对于 JVM 平台, 可以绕过这个问题: 你需要添加 @JvmOverloads 注解.
对于跨平台项目, 没有变通方法.
不要在 API 中使用数据类
我们通常会使用 数据类(Data Class), 因为它们代码短, 简洁, 而且自动提供了很多好的功能. 但是, 由于数据类工作方式的某些细节, 在库的 API 中最好不要使用它们. 几乎任何变更都会导致 API 不能向后兼容.
一般来说, 很难预测随着时间的推移你将会需要如何修改一个类. 即使今天你认为这个类是独立的, 但没有办法确信你的需求在未来不会变化. 因此, 只有在你决定修改一个这样的类的时候, 数据类的这些问题才会发生.
首先, 上一节中介绍过的需要注意的问题, 不要向既有的 API 函数添加参数, 同样适用于构造器, 因为它也是一个方法. 第二, 即使你添加了次级构造器(Secondary Constructor), 也不能解决兼容性问题. 我们来看看下面的数据类:
data class User(
val name: String,
val email: String
)
例如, 随着时间的推移, 你发现用户需要办理一个激活过程, 因此你想要添加一个新的域变量, "active", 默认值为 "true". 这个新的域变量应该能够让既有的代码不需要修改就能正常工作.
在 上一节 中我们已经讨论过, 你不能仅仅只是添加新的域变量, 如下:
data class User(
val name: String,
val email: String,
val active: Boolean = true
)
因为这个变更是 二进制不兼容的.
我们来添加一个新的构造器, 它只接受 2 个参数, 并对第 3 个参数使用默认值来调用主构造器:
data class User(
val name: String,
val email: String,
val active: Boolean = true
) {
constructor(name: String, email: String) :
this(name, email, active = true)
}
现在有了 2 个构造器, 而且其中一个的签名与修改之前的类的构造器一致:
public User(java.lang.String, java.lang.String);
但问题不在于构造器 – 而出在 copy 函数. 它的签名发生了变更, 之前是:
public final User copy(java.lang.String, java.lang.String);
现在是:
public final User copy(java.lang.String, java.lang.String, boolean);
这个变更导致代码 二进制不兼容.
当然, 可以数据类的内部添加一个属性, 但这样就失去了数据类的所有优点. 因此, 在你的 API 中最好不要使用数据类, 因为对数据类的几乎所有变更都会破坏源代码兼容性, 二进制兼容性, 或行为兼容性.
如果你出于某种原因必须使用数据类, 那么你需要覆盖构造器和 copy() 方法.
此外, 如果你向类的 Body 部添加一个域变量, 你需要覆盖 hashCode() 和 equals() 方法.
交换参数的顺序永远是一种不兼容的变更, 因为
componentX()方法发生了变化. 这样的变更会破坏源代码兼容性, 可能也会破坏二进制兼容性.
不要降低返回值类型的范围
有些情况下, 尤其是如果你没有使用 明确 API 模式(Explicit API Mode),
返回值类型声明可能发生隐含的变化.
但即使在这样的情况之外, 你也可能会降低返回值类型的范围.
例如, 你可能发现需要使用下标索引来访问你的集合中的元素, 并且希望将返回值类型从 Collection 修改为 List.
放宽返回值类型的范围通常会破坏源代码兼容性; 例如, 将 List 转换为 Collection, 会破坏所有使用下标索引访问元素的代码.
降低返回值类型的范围通常是源代码兼容的变更, 但会破坏二进制兼容性, 本节会进行解释.
我们来看看 library.kt 文件中的一个库函数:
public fun x(): Number = 3
在 client.kt 文件中对这个函数的使用示例:
fun main() {
println(x()) // 输出结果为 3
}
我们使用 kotlinc library.kt client.kt 编译它, 并确认它能够正确工作:
$ kotlin ClientKt
3
下面我们将 "库" 函数 x() 返回值类型从 Number 改为 Int:
fun x(): Int = 3
并且只重编译客户端: kotlinc client.kt.
现在 ClientKt 不能再象期望的那样工作了.
它不会输出 3, 而是抛出一个异常:
Exception in thread "main" java.lang.NoSuchMethodError: 'java.lang.Number Library.x()'
at ClientKt.main(call.kt:2)
at ClientKt.main(call.kt)
...
发生这个问题是因为字节码中下面的这行:
0: invokestatic #12 // 方法 Library.x:()Ljava/lang/Number;
这行的意思是, 你调用返回类型为 Number 的静态方法 x().
但这个方法已经不存在了, 因此 二进制兼容性被破坏了.
@PublishedApi 注解
有些时候, 你可能需要使用你的一部分内部 API, 来实现 内联函数(Inline Function).
你可以通过 @PublishedApi 注解达到这个目的.
你应该将标注了 @PublishedApi 的代码看作是 Public API 的一部分,
因此, 你应该小心注意向后兼容性问题.
@RequiresOptIn 注解
有些时候, 你可能想要让用户试用你的 API.
在 Kotlin 中, 有很好的方法将某些 API 定义为不稳定状态 – 使用 @RequiresOptIn 注解.
但是, 要注意以下问题:
- 如果你很长时间没有修改你的 API 的某个部分, 而且它已经处于稳定状态, 你应该重新考虑是否使用
@RequiresOptIn注解. - 你可以使用
@RequiresOptIn注解来对 API 的不同部分定义不同的保证级别: 预览版, 实验版, 内部版, Delicate, 或 Alpha, Beta, RC. - 你应该明确定义各个 级别 代表什么含义, 编写 KDoc 注释, 并添加警告信息.
如果你依赖于一个 API 明确要求使用者同意, 不要使用 @OptIn 注解.
要使用 @RequiresOptIn 注解, 这样可以让你的用户能够有意识的选择他们想要哪个 API, 不想要哪个 API.
@RequiresOptIn 的另一个例子是, 如果你想要在使用者使用某个 API 时明确的提出警告.
例如, 如果你在维护一个库, 它利用了 Kotlin 的反射功能, 你可以对这个库中的类添加 @RequiresFullKotlinReflection 注解.
明确 API 模式(Explicit API Mode)
你应该让你的 API 保持尽可能的清楚明白. 为了强制让 API 清楚明白, 请使用 明确 API 模式(Explicit API Mode).
Kotlin 给了你很大的自由度来决定如何编写代码. 可以省略类型定义, 可见度声明, 或文档. 明确 API 模式强制要求你(作为开发者), 将这些隐含的信息明确的定义清楚. 在上面的链接中, 你可以看到如何启用这个功能. 我们来理解一下你为什么需要这个功能:
-
不使用明确 API 模式, 会很容易破坏向后兼容性:
// 版本 1 fun getToken() = 1 // 版本 1.1 fun getToken() = "1"getToken()的返回类型发生了变化, 而你甚至不需要修改它的签名, 就破坏了使用者的代码. 他们期望的返回值是Int, 但实际得到的是String. -
对可见度也是如此. 如果
getToken()函数是private, 那么向后兼容性不会被破坏. 但如果没有明确的可见度声明, 就不清楚 API 的使用者是否应该能够访问它. 如果使用者应该可以访问, 那么应该声明为public, 并添加文档; 这种情况下, 上面的变更会破坏向后兼容性. 如果使用者不应该可以访问, 那么应该声明为private或internal, 上面的变更就不会造成破坏.
用于增强向后兼容性的工具
在软件开发中, 向后兼容性是一个至关重要的方面, 因为它能够确保库或框架的新版本能够与既有的代码一起使用, 而不引起任何问题. 维护向后兼容性可能成为一项困难而且耗费时间的任务, 尤其是在处理大型代码库, 或复杂 API 的时候. 向后兼容性很难手动维护, 而且开发者经常需要依赖于测试和手动检查来确保新的变更不会破坏既有的代码. 为了解决这个问题, JetBrains 创建了 二进制兼容性验证器, 此外还有另一个解决方案: japicmp.
目前, 这两个工具都只能用于 JVM 平台.
这两个解决方案都有它们的优点和缺点. japicmp 可以用于任何 JVM 语言, 而且它既是一个 CLI 工具, 也是一个构建系统 plugin. 但是, 它要求应用程序的旧版本和新版本都以 JAR 文件形式提供. 如果你不能得到你的库的旧版本的构建, 它就不那么容易使用了. 而且, japicmp 会给出 Kotlin metadata 的变更信息, 你可能并不需要 (因为 metadata 格式并没有明确的规格, 而且它只供 Kotlin 内部使用).
二进制兼容性验证器只能作为 Gradle plugin 使用, 而且它还处于 Alpha 阶段. 它不需要访问 JAR 文件. 它只需要以前的 API 和当前 API 的特定的 dump. 它能够自己收集这些 dump. 关于这些工具, 详情请阅读下文.
二进制兼容性验证器
二进制兼容性验证器 是一个工具, 它自动检测并报告 API 中的破坏性变更, 帮助确保你的库和框架的向后兼容性. 这个工具分析你进行修改之前和之后的库的字节码, 并比较两个版本, 找出可能破坏既有代码的变更. 这使得你可以在问题暴露给使用者之前, 更加容易的检测并修复问题.
这个工具可以节约你在手动测试和检查上耗费的大量的时间和精力. 它还能帮助防止 API 中的破坏性变更可能造成的问题. 最终可以带来更好的用户体验, 因为用户能够依赖于库和框架的稳定性和兼容性.
japicmp
如果你的开发平台只有 JVM, 你也可以使用 japicmp. japicmp 工作的层级与二进制兼容性验证器不同: 它比较两个 jar 文件 – 旧版本和新版本 – 并报告它们之间的不兼容性.
要注意, japicmp 不仅仅报告不兼容性, 还包括不会对使用者造成任何影响的变更. 例如, 对于下面的代码:
class Calculator {
fun add(a: Int, b: Int): Int = a + b
fun multiply(a: Int, b: Int): Int = a * b
}
如果你添加一个新的方法, 并不破坏兼容性, 如下:
class Calculator {
fun add(a: Int, b: Int): Int = a + b
fun multiply(a: Int, b: Int): Int = a * b
fun divide(a: Int, b: Int): Int = a / b
}
japicmp 会报告以下变更:
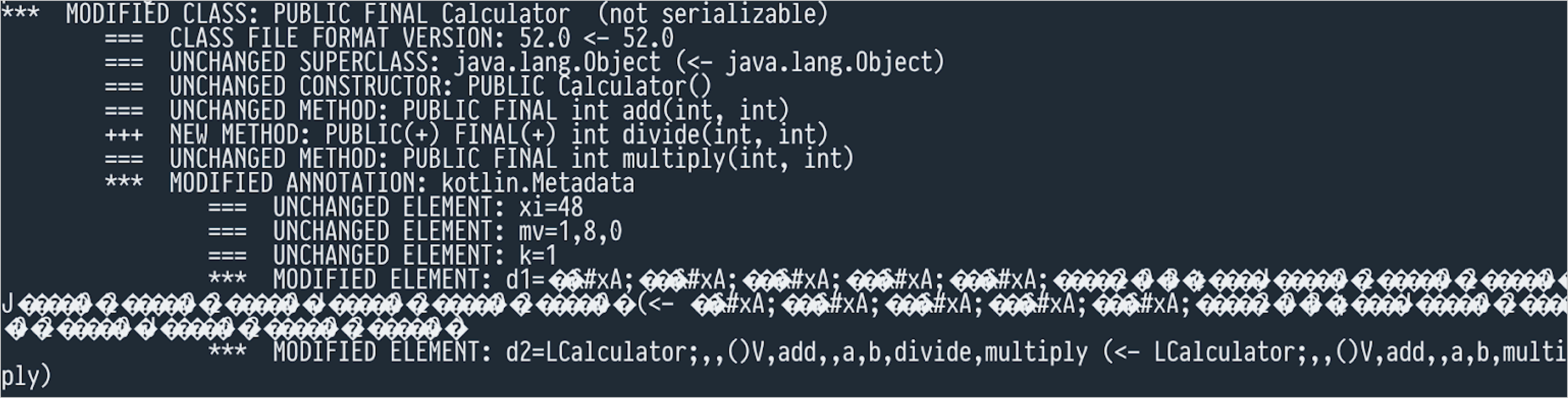
这仅仅是在 @Metadata 注解中的变更, 并没有什么重要意义, 但 japicmp 并不理解 JVM 语言, 必须报告它发现的一切变更.